基于LoRA训练及部署3GPP规范问答大模型详细指南
来自知识星球

基于LoRA训练及部署3GPP规范问答大模型详细指南

您有没有这样的痛点?
下载了几百本规范,不知道看哪个?
用搜索方式去搜关键字,搜出来还是看不懂?
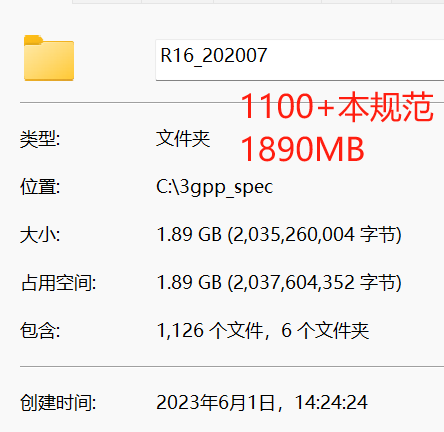
想不想用下载的1000本规范作为训练数据,去训练一个属于自己的3GPP规范大模型?
如果您有这样的痛点,那得去看我们的另一篇文章,本文就不太适合您了。本文的解决方案是LORA。
LORA不能独立存在,还需要一个基础大模型(比如Deepseek来打底)。
不管是本地部署,还是用云端GPU,成本都非个人所能承担。如果是1000本规范,那就最好用RAG了。
以后单独发文。
LORA当然也能训练1000本规范,但会血亏。
• 本文主要解决一个什么痛点呢?
• 假设我不需要训练1000本规范,我就想训练1本规范23.501(5G网元、功能、架构、特性),最新版
的R18.9的23.501规范,2025年3月发布,63万字,319万字符,训练可是按319万字符收费哦。
• 那您可以考虑本文的方案,这时候LORA的性价比就比RAG可能要高了。

针对单一规范(23.501)的解决方案
针对只关注23.501这一本规范的情况,对于这种情况,LoRA微调确实可能比RAG更有性价比。
LoRA微调方案
• 一次训练后可离线使用,不需持续检索
• 对单一文档(30万字)的训练成本可接受
• 可能对3GPP特定术语和表达有更好理解
具体实施步骤
1. 准备训练数据
1. 将23.501 PDF转换为纯文本
2. 构建问答对数据集:
- 从目录提取主题创建问题
- 从章节内容生成答案
- 创建200-300个高质量QA对
2. 选择基础模型
- Qwen2-7B或ChatGLM3-6B(中文支持较好)
- Llama-3-8B-Instruct(如需平衡中英文能力)
3. LoRA训练配置
- rank: 8-16
- alpha: 16-32
- 学习率: 2e-4到5e-4
- epochs: 3-5
4. 硬件需求
- 最低: 16GB显存GPU(如RTX 3090/4070Ti)
- 训练时间: 约2-4小时
5. 验证与部署
- 创建特定于23.501的测试问题集
- 本地部署用Ollama或text-generation-webui
与RAG方案对比
针对单一规范,LoRA微调优势更明显:
• 成本: 单次训练成本(几小时GPU时间)vs持续运行向量数据库
• 延迟: 推理速度更快,无需实时检索
• 整合性: 模型可能更好地理解规范内不同章节间的关联
混合方案(可选)
最佳方案可能是轻量级LoRA微调+小型RAG:
1. 用LoRA捕获规范的大部分知识和术语
2. 用小型RAG处理需要精确引用的查询
对于单一23.501规范,LoRA微调确实比纯RAG更有性价比。如未来需扩展到更多规范,可以:
1. 先充分利用这个专精于23.501的模型
2. 逐步将其他关键规范通过类似方式训练
3. 对于不常用规范采用RAG补充
基于LoRA训练3GPP通信专业模型详细指南
一、代码实现(本地或云环境通用)
1. 环境配置
# 创建虚拟环境
conda create -n telecom_llm python=3.10
conda activate telecom_llm
# 安装依赖
pip install torch==2.1.0 transformers==4.34.0 datasets==2.14.5 peft==0.5.0
pip install accelerate==0.23.0 bitsandbytes==0.41.1 trl==0.7.2
pip install sentencepiece protobuf scipy
2. 数据准备脚本
# prepare_data.py
import json
import os
import re
from pypdf import PdfReader
def extract_sections_from_pdf(pdf_path):
"""从PDF中提取各个章节及内容"""
reader = PdfReader(pdf_path)
full_text = ""
for page in reader.pages:
full_text += page.extract_text() + "\n"
# 使用正则表达式识别3GPP规范中的章节结构
# 这里的正则表达式需要根据实际PDF格式调整
section_pattern = r'(\d+(?:\.\d+)*)\s+([^\n]+)\n'
sections = re.findall(section_pattern, full_text)
# 提取每个章节的内容
section_contents = {}
for i, (section_num, section_title) in enumerate(sections):
start_pos = full_text.find(f"{section_num} {section_title}")
if i < len(sections) - 1:
next_section = sections[i+1][0] + " " + sections[i+1][1]
end_pos = full_text.find(next_section)
else:
end_pos = len(full_text)
content = full_text[start_pos:end_pos].strip()
section_contents[section_num] = {
"title": section_title,
"content": content
return section_contents
def create_qa_pairs(sections):
"""基于章节创建问答对"""
qa_pairs = []
# 为每个章节创建问答对
for section_num, section_data in sections.items():
title = section_data["title"]
content = section_data["content"]
# 创建关于章节标题的问题
qa_pairs.append({
"instruction": f"请详细解释3GPP规范23.501中的'{title}'(章节{section_num})是什么?",
"input": "",
"output": f"在3GPP TS 23.501规范中,第{section_num}章节'{title}'主要内容如
下:\n\n{content[:1500]}..."
# 创建关于章节内容的问题
qa_pairs.append({
"instruction": f"请详细介绍3GPP TS 23.501中第{section_num}章节的主要内容",
"input": "",
"output": f"3GPP TS 23.501第{section_num}章节'{title}'的主要内容包
括:\n\n{content[:1500]}..."
# 为较长的章节创建多个问答对,关注不同方面
if len(content) > 1000:
# 可以基于内容特点创建更多问题
keywords = ["架构", "功能", "接口", "流程", "参考点", "协议", "信令"]
for keyword in keywords:
if keyword in content or keyword in title:
qa_pairs.append({
"instruction": f"请详细解释3GPP TS 23.501中第{section_num}章节关于{keyword}的
部分",
"input": "",
"output": f"在3GPP TS 23.501规范的第{section_num}章节('{title}')中,关于
{keyword}的描述如下:\n\n{content[:1500]}..."
# 创建一些跨章节的问题
qa_pairs.append({
"instruction": "简要概述3GPP TS 23.501规范的主要内容和结构",
"input": "",
"output": "3GPP TS 23.501是5G系统架构的核心规范文档,定义了5G系统的整体架构、网络功能、接口和
参考点。主要内容包括:\n\n1. 5G系统架构原则和要求\n2. 5G系统的整体架构\n3. 网络功能和参考点\n4. 身份识
别和寻址\n5. 策略控制与计费\n6. 会话管理\n7. QoS机制\n8. 网络切片\n9. 网络能力开放\n10. 5G系统与EPS的
互通\n\n该规范是理解5G网络架构和功能的基础文档,为系统实现和互操作提供了技术基础。"
return qa_pairs
def main():
# 处理PDF
sections = extract_sections_from_pdf("3GPP_TS_23.501.pdf")
# 创建问答对
qa_pairs = create_qa_pairs(sections)
# 保存为训练数据
with open("3gpp_training_data.json", "w", encoding="utf-8") as f:
json.dump(qa_pairs, f, ensure_ascii=False, indent=2)
print(f"成功生成{len(qa_pairs)}个训练样本")
if __name__ == "__main__":
main()
3. LoRA训练脚本
# train_lora.py
import os
import json
import torch
import logging
from datasets import Dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
Trainer,
DataCollatorForSeq2Seq
from peft import (
get_peft_model,
LoraConfig,
TaskType,
prepare_model_for_kbit_training
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# 配置参数
MODEL_NAME = "Qwen/Qwen1.5-7B-Chat" # 或 "THUDM/chatglm3-6b"
OUTPUT_DIR = "./3gpp_lora_model"
LORA_R = 16
LORA_ALPHA = 32
LORA_DROPOUT = 0.1
LEARNING_RATE = 2e-4
BATCH_SIZE = 2
GRADIENT_ACCUMULATION_STEPS = 4
NUM_EPOCHS = 3
MAX_SEQ_LENGTH = 2048
def prepare_dataset(data_path):
"""准备训练数据集"""
with open(data_path, "r", encoding="utf-8") as f:
data = json.load(f)
# 根据模型选择正确的提示词格式
if "Qwen" in MODEL_NAME:
# Qwen模型格式
formatted_data = []
for item in data:
if item["input"]:
prompt = f"<|im_start|>user\n{item['instruction']}\n{item['input']}
<|im_end|>\n<|im_start|>assistant\n"
else:
prompt = f"<|im_start|>user\n{item['instruction']}
<|im_end|>\n<|im_start|>assistant\n"
response = f"{item['output']}<|im_end|>"
formatted_data.append({"prompt": prompt, "response": response})
elif "chatglm" in MODEL_NAME.lower():
# ChatGLM模型格式
formatted_data = []
for item in data:
if item["input"]:
prompt = f"[Round 1]\n\n问:{item['instruction']}\n{item['input']}\n\n答:"
else:
prompt = f"[Round 1]\n\n问:{item['instruction']}\n\n答:"
response = item['output']
formatted_data.append({"prompt": prompt, "response": response})
else:
# 通用格式(如Llama等)
formatted_data = []
for item in data:
if item["input"]:
prompt = f"<s>[INST] {item['instruction']}\n{item['input']} [/INST]"
else:
prompt = f"<s>[INST] {item['instruction']} [/INST]"
response = f"{item['output']}</s>"
formatted_data.append({"prompt": prompt, "response": response})
dataset = Dataset.from_list(formatted_data)
return dataset
def tokenize_function(examples, tokenizer):
"""将文本处理为模型输入格式"""
full_texts = []
for i in range(len(examples["prompt"])):
full_text = examples["prompt"][i] + examples["response"][i]
full_texts.append(full_text)
tokenized = tokenizer(
full_texts,
padding="max_length",
truncation=True,
max_length=MAX_SEQ_LENGTH,
return_tensors="pt"
# 创建标签,-100表示不计算loss
tokenized["labels"] = tokenized["input_ids"].clone()
# 将prompt部分的标签设为-100
for i in range(len(examples["prompt"])):
prompt_len = len(tokenizer(examples["prompt"][i], return_tensors="pt")["input_ids"][0])
tokenized["labels"][i, :prompt_len] = -100
return tokenized
def train():
logger.info(f"使用模型: {MODEL_NAME}")
# 量化配置
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True
# 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, trust_remote_code=True)
# 确保tokenizer有正确的pad_token
if tokenizer.pad_token is None:
if tokenizer.eos_token:
tokenizer.pad_token = tokenizer.eos_token
else:
tokenizer.pad_token = tokenizer.eos_token = "</s>"
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
torch_dtype=torch.float16
# 准备用于量化训练的模型
model = prepare_model_for_kbit_training(model)
# 配置LoRA
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=LORA_R,
lora_alpha=LORA_ALPHA,
lora_dropout=LORA_DROPOUT,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"] # 可能需要根据模型调整
model = get_peft_model(model, peft_config)
# 准备数据集
dataset = prepare_dataset("3gpp_training_data.json")
# 数据集处理
tokenized_dataset = dataset.map(
lambda examples: tokenize_function(examples, tokenizer),
batched=True,
remove_columns=["prompt", "response"]
# 训练参数
training_args = TrainingArguments(
output_dir=OUTPUT_DIR,
per_device_train_batch_size=BATCH_SIZE,
gradient_accumulation_steps=GRADIENT_ACCUMULATION_STEPS,
learning_rate=LEARNING_RATE,
num_train_epochs=NUM_EPOCHS,
weight_decay=0.01,
save_strategy="epoch",
fp16=True,
logging_steps=10,
report_to="none"
# 数据整理器
data_collator = DataCollatorForSeq2Seq(
tokenizer,
pad_to_multiple_of=8,
return_tensors="pt",
padding=True
# 初始化训练器
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
data_collator=data_collator,
# 开始训练
logger.info("开始训练...")
trainer.train()
# 保存模型
logger.info(f"保存模型到 {OUTPUT_DIR}")
model.save_pretrained(OUTPUT_DIR)
tokenizer.save_pretrained(OUTPUT_DIR)
logger.info("训练完成!")
if __name__ == "__main__":
train()
4. 推理测试脚本
# test_model.py
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
# 加载模型配置
peft_model_path = "./3gpp_lora_model"
config = PeftConfig.from_pretrained(peft_model_path)
base_model_name = config.base_model_name_or_path
# 加载基础模型
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True
tokenizer = AutoTokenizer.from_pretrained(base_model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
base_model_name,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True
# 加载LoRA权重
model = PeftModel.from_pretrained(model, peft_model_path)
# 设置生成参数
generate_kwargs = {
"max_new_tokens": 1024,
"temperature": 0.7,
"top_p": 0.9,
"repetition_penalty": 1.1,
"do_sample": True
# 准备提示词模板
def prepare_prompt(question, model_name):
if "Qwen" in model_name:
return f"<|im_start|>user\n{question}<|im_end|>\n<|im_start|>assistant\n"
elif "chatglm" in model_name.lower():
return f"[Round 1]\n\n问:{question}\n\n答:"
else:
return f"<s>[INST] {question} [/INST]"
# 测试问题
test_questions = [
"请解释5G系统架构中的AMF功能实体是什么?",
"5G核心网中SMF与UPF之间的接口是什么?它们之间有什么交互?",
"QoS Flow ID (QFI)在5G QoS机制中的作用是什么?",
"请详细介绍5G中网络切片选择的流程",
"5G系统的服务化架构与4G有什么主要区别?"
# 进行推理
for question in test_questions:
prompt = prepare_prompt(question, base_model_name)
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
print(f"\n问题: {question}")
print("=" * 50)
with torch.no_grad():
outputs = model.generate(
**inputs,
**generate_kwargs
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 根据模型格式提取回答部分
if "Qwen" in base_model_name:
response = response.split("<|im_start|>assistant\n")[-1].replace("<|im_end|>", "")
elif "chatglm" in base_model_name.lower():
response = response.split("答:")[-1]
else:
response = response.split("[/INST]")[-1].strip()
print(f"回答: {response}")
print("=" * 50)
print("\n")
二、百度智能云上的训练步骤
1. 准备阶段
1. 注册百度智能云账号:
• 访问 https://cloud.baidu.com/ 注册账号
• 完成实名认证(企业或个人)
2. 充值余额:
• 根据训练预算充值足够余额
• 计划至少500-1000元用于训练实验
3. 开通EasyDL服务:
• 导航至"百度智能云 > 人工智能 > EasyDL"
• 开通"EasyDL定制化训练"服务
2. 数据准备与上传
1. 准备数据集:
• 按照上述代码准备好3GPP TS 23.501的训练数据
• 确保数据格式符合EasyDL要求(通常支持JSON格式)
2. 数据上传:
1. 进入EasyDL平台
2. 创建"大语言模型定制"项目
3. 选择"数据管理 > 上传数据"
4. 上传准备好的JSON格式训练数据
3. 训练配置与启动
1. 选择基础模型:
1. 选择"模型训练"
2. 基础模型选择"千帆大模型"(推荐)或其他支持的开源模型
3. 选择7B-13B规模的模型作为基座
2. 配置训练参数:
1. 训练方式选择"LoRA微调"
2. LoRA参数设置:
- rank: 16
- alpha: 32
- dropout: 0.1
3. 学习率: 2e-4
4. 训练轮次: 3-5
5. 批量大小: 根据所选GPU自动调整或手动设置
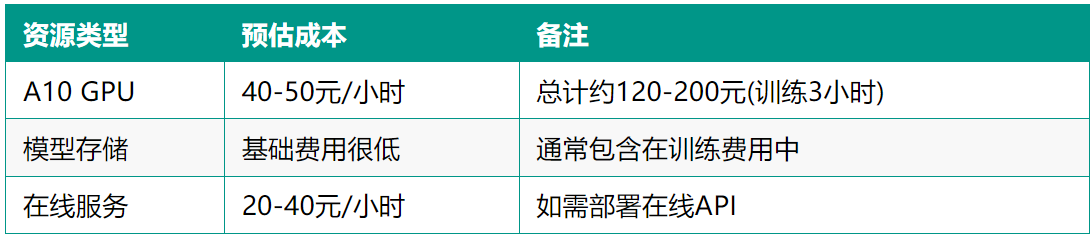
3. 选择计算资源:
1. 选择"A10"或"V100"GPU
2. 配置训练时长估计:
- 对于~300样本,3轮次约需2-4小时
4. 启动训练:
1. 确认配置并提交训练任务
2. 记录训练ID便于后续查询
4. 模型部署与导出
1. 完成训练后:
1. 在"模型服务"页面查看训练完成的模型
2. 可选择在线部署或离线导出
2. 导出模型:
1. 选择"模型导出"
2. 选择"仅导出LoRA权重"选项(节省空间)
3. 下载模型文件包
三、科大讯飞云上的训练步骤
1. 准备阶段
1. 注册讯飞开放平台账号:
• 访问 https://www.xfyun.cn/ 注册账号
• 完成实名认证
2. 开通星火大模型平台:
• 进入"控制台 > 星火大模型"
• 开通星火大模型服务
3. 充值/购买算力包:
• 购买适当的算力资源包
• 建议选择"星火大模型训练专用算力包"
2. 数据准备与训练配置
1. 数据准置与上传:
1. 进入"星火大模型平台 > 微调训练"
2. 创建数据集并上传准备好的JSON文件
3. 设置数据集格式为问答对
2. 创建训练任务:
1. 选择"创建训练任务"
2. 选择基础模型(讯飞星火或其支持的开源模型)
3. 选择微调方式为"LoRA"
4. 配置训练参数:
- LoRA rank: 16
- 学习率: 2e-4
- Epoch: 3-5
- 批次大小: 根据选择的GPU自动优化
3. 启动训练:
1. 选择GPU资源(建议A10或同等配置)
2. 确认费用并提交训练任务
四、成本估算
1. 本地训练成本

2. 百度智能云成本
3. 科大讯飞云成本

五、推荐方案与后续部署
最佳推荐方案
1. 方案选择:
• 如有本地GPU: 自行训练最划算
• 如无GPU资源: 百度智能云最为成熟和经济
2. 成本效益最佳路径:
1. 先小规模实验(100样本)评估效果
2. 确认效果后再扩大训练集(300-500样本)
3. 最终训练完成后导出模型至本地部署
本地部署步骤
1. 安装部署环境:
# 创建新环境
conda create -n 3gpp_deploy python=3.10
conda activate 3gpp_deploy
# 安装依赖
pip install torch transformers peft accelerate bitsandbytes
pip install gradio # 用于Web界面
2. 部署Web界面:
# deploy.py
import gradio as gr
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
# 加载模型
model_path = "./3gpp_lora_model" # 或云平台下载的模型路径
config = PeftConfig.from_pretrained(model_path)
# 量化配置
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16
# 加载tokenizer和模型
tokenizer = AutoTokenizer.from_pretrained(
config.base_model_name_or_path,
trust_remote_code=True
model = AutoModelForCausalLM.from_pretrained(
config.base_model_name_or_path,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True
# 加载LoRA权重
model = PeftModel.from_pretrained(model, model_path)
model.eval()
# 准备提示词函数
def prepare_prompt(question, model_name):
if "Qwen" in model_name:
return f"<|im_start|>user\n{question}<|im_end|>\n<|im_start|>assistant\n"
elif "chatglm" in model_name.lower():
return f"[Round 1]\n\n问:{question}\n\n答:"
else:
return f"<s>[INST] {question} [/INST]"
# 推理函数
def predict(question):
prompt = prepare_prompt(question, config.base_model_name_or_path)
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=1024,
temperature=0.7,
top_p=0.9,
repetition_penalty=1.1,
do_sample=True
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 提取回答部分
if "Qwen" in config.base_model_name_or_path:
response = response.split("<|im_start|>assistant\n")[-1].replace("<|im_end|>", "")
elif "chatglm" in config.base_model_name_or_path.lower():
response = response.split("答:")[-1]
else:
response = response.split("[/INST]")[-1].strip()
return response
# 创建Gradio界面
demo = gr.Interface(
fn=predict,
inputs=gr.Textbox(lines=5, placeholder="请输入您的3GPP相关问题..."),
outputs=gr.Textbox(label="回答"),
title="3GPP TS 23.501专家系统",
description="基于LoRA微调的通信技术专家模型,专注于5G系统架构(TS 23.501)"
# 启动界面
if __name__ == "__main__":
demo.launch(server_name="0.0.0.0", share=False) # 设置share=True可获得公网访问链接
3. 启动服务:
python deploy.py
后续扩展建议
1. 逐步扩充专业领域:
• 完成23.501后,可以逐步添加23.502(流程)、23.503(策略)训练
• 逐步构建完整的5G专业知识体系
2. 结合RAG增强能力:
• 对于其他非核心规范,可采用RAG方式补充
• 构建混合系统:核心知识用LoRA微调,补充知识用RAG
3. 性能优化:
• 考虑模型量化为4-bit或8-bit以降低资源需求
• 使用vLLM等推理引擎加速部署效果
可按照上述指南循序渐进,先完成单本规范的训练,确认效果满意后再扩展。整体成本控制在500-1000
元范围内是完全可行的。